在深入研究Nanite的过程中, 发现Nanite使用了双Pass遮挡剔除的技术. 之前对此技术也略有耳闻, 但一直未深入了解. 恰巧也发现一篇不错的关于双Pass遮挡剔除的英文博客, 特以本文翻译学习一波~
参考材料
1. Two-Pass Occlusion Culling
2. 理解Nanite(一):遮挡剔除
3. 19.7 遮挡剔除
遮挡剔除是一种通过跳过场景中被其它物体遮挡的物体渲染来提升性能的优化技术. 目前存在多种遮挡剔除方法, 但它们各自存在不同的问题, 例如: 可见性Popping, 数据制作复杂性以及性能损耗. 现代实时渲染中的一种流行方法是基于GPU驱动的剔除技术, 称为层次$Z$缓冲(HZB, Hierarchical $Z$-Buffer) 遮挡剔除. 然而, 这一方法也存在显著缺陷, 因此双Pass HZB遮挡剔除被提出以改进其不足.
1. HZB遮挡剔除概述
HZB本质上是一条通过下采样深度缓冲生成的MIP链, 其生成方式是: 对每组4个纹素取其最小或最大深度值, 作为下一级MIP层对应的新纹素值. 具体使用最小值还是最大值, 取决于是否启用了Reversed-$Z$. 随后, 可通过物体的包围体与HZB进行对比, 从而实现遮挡剔除. 除了遮挡剔除, HZB还可用于体积雾, 屏幕空间反射等渲染技术.
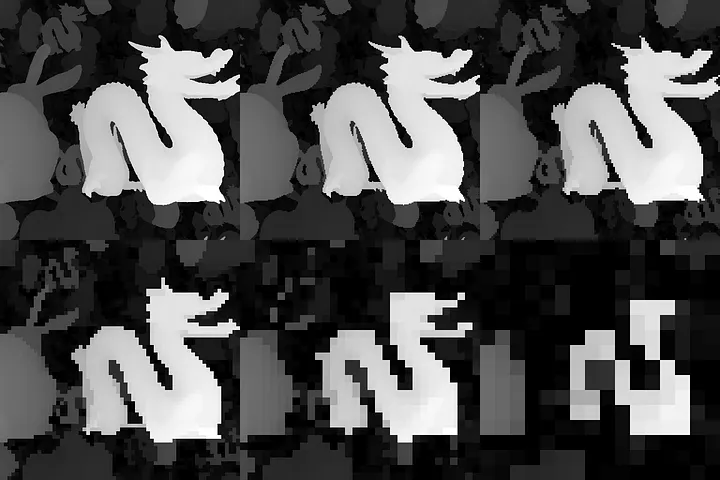
有几种方法可以优化HZB的构建过程. 其中两种技术是纹理聚集(Texture Gathering) 和采样器缩减模式(Sampler Reduction Modes), 二者均能减少纹理采样的次数, 从而提升性能.
$\\$ 利用AABB对HZB进行测试, 这一过程通常在Compute Shader中完成. 该Shader Dispatch的输出结果通常是一组Indirect Draw Call Arguments, 这些参数仅描述当前可见的物体. 随后, 这些参数会被用于执行一次Indirect Draw Call.
$\\$ HZB遮挡测试首先需要选择合适的MIP层级. 其核心目标是找到一个层级, 使得当前物体的AABB在该层级中恰好覆盖4个相邻的纹素. 这一选择通常通过一个对数方程实现, 该方程会结合AABB的长宽尺寸进行计算. 当HZB的宽度与高度不相等时(例如非正方形的深度缓冲), MIP层级的选择会略微复杂化.
// MIP level selection example int mipLevel = floor(log2(max(AABB.pixelWidth, AABB.pixelHeight)));
完成合适的MIP层级选择后, 需比较上述4个纹素的深度值与物体距离摄像机最近点的深度值. 通过这一比较结果, 可以判断物体是否被剔除. 当整个场景的遮挡测试完成后, 通过测试的物体即可进行渲染.
2. 问题
如前所述, 构建HZB需要依赖深度缓冲区. 但问题在于: 这一深度缓冲区最初是如何获取的? 有人可能会认为需要先渲染所有物体才能填充深度缓冲区, 但这会从根本上抵消遮挡剔除技术的意义(因为剔除的目的正是避免渲染不可见物体).
3. 潜在解决方案
一种常见方法涉及渲染一小部分物体作为遮挡体. 这些遮挡体通常由艺术家手动挑选和制作, 通常是大型物体(如建筑物, 墙壁和地形). 遮挡体的渲染仅写入深度缓冲区, 不执行Pixel Shader, 这一过程称为Death Prepass. 通过生成的深度缓冲区, 可以构建一个不完整但保守的HZB. 这一HZB随后用于遮挡剔除流程. 尽管该方法有效, 但其维护需要大量人工干预.

在许多场景中, 可以合理假设: 前一帧中可见的物体在当前帧中仍可能保持可见. 利用这一观察, 一种解决方案是复用前一帧的深度缓冲区, 以此生成当前帧新深度缓冲区的近似值. 这一技术被称为深度缓冲重投影, 其实现需结合当前帧的摄像机变换和前一帧的速度向量缓冲区.
$\\$ 深度重投影还可用于构建Shadow Map的HZB. 其显著优势在于: 减少手动选择遮挡体的必要性. 然而, 将深度重投影与手动遮挡体选择结合使用, 通常能获得更优的效果. 育碧2014年发布的《刺客信条: 大革命》中即采用了该技术.


尽管深度缓冲重投影技术具有诸多优势, 但它也存在显著局限性. 其中一个主要问题是精度问题: 由于HZB的构建依赖于对深度缓冲的近似估算, 遮挡剔除过程在某些情况下可能变得非保守(即可能错误地剔除本应可见的物体). 这会导致可见性Popping等问题—— 当物体与摄像机相对运动时, 物体可能突然出现在画面中(而非渐进式显现).
4. 双Pass解决方案
结合前文提到的两种解决方案的优势, 可以实现两者的最佳平衡: 既保留Depth Prepass的精度, 又避免深度缓冲重投影所需的手动数据标注. 提出的解决方案与深度缓冲重投影有相似之处, 即复用前一帧的数据, 但不同之处在于—— 并非重投影深度值, 而是仅重投影前一帧中可见的物体. 技术实现流程:
$\\$ $\cdot$ 第一次Pass
$\\$ 1) 在当前帧的渲染初始阶段, 渲染前一帧中可见的物体(如角色, 动态物体或小型几何体).
$\\$ 2) 这些物体作为当前帧的理想遮挡体候选, 假设摄像机运动幅度不大(避免因视角剧烈变化导致遮挡关系失效).
$\\$ 3) 与Depth Prepass不同, 第一次Pass通常不仅存储深度信息, 还可能包含额外数据(如法线, 材质属性), 具体取决于渲染管线:
$\\$ a) 延迟渲染: 生成G-Buffers.
$\\$ b) 前向渲染: 仅写入深度和基础颜色信息.
$\\$ $\cdot$ 第二次Pass(标准的HZB遮挡剔除)
$\\$ 1) 基于第一次Pass生成的深度和几何数据构建HZB.
$\\$ 2) 通过HZB进行遮挡测试, 剔除当前帧中不可见的物体.
$\\$ 顾名思义, 双Pass遮挡剔除的核心思想是将场景中的物体划分为两组, 并通过两次独立的渲染Pass处理. 每一次Pass由一次Compute Shader Dispatch组成, 其目标是生成Indirect Draw Call Arguments. 随后, 这些参数会被用于执行一次Indirect Draw Call, 若硬件支持Multi Draw Count Indirect特性, 则可进一步优化性能. 这一技术与GPU-Driven Pipeline高度契合.
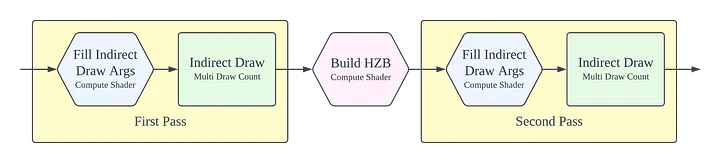
4.1 第一次Pass
如前所述, 第一次Pass仅负责处理前一帧中可见的物体. 为实现这一目标, Dispatch一个Compute Shader, 其线程数量与场景中的物体总数相同. 此外, 每个线程可对前一帧可见的物体执行可选的视锥体剔除和LOD选择, 而完全跳过前一帧不可见的物体. 该Compute Shader的结果会被存储在GPU缓冲区中作为Indirect Draw Call Arguments.
$\\$ 在收集完Indirect Draw Call Arguments后, 这些参数会通过一次Indirect Draw Call执行. 为了跟踪前一帧中物体的可见性状态, 需使用另一个GPU缓冲区—— Visibility Buffer. 该缓冲区的每个元素对应场景中的一个物体:
$\\$ $\cdot$ 0表示物体不可见,
$\\$ $\cdot$ 1表示物体可见.
$\\$ Visibility Buffer初始化时应填充值为全0(默认不可见) 或全1(默认可见). 此外, 单个缓冲区元素中可以打包多个可见性位标志(例如通过位掩码实现多帧可见性状态存储).
...
// Read object's visibility from the previous frame
bool visible = visibilityBuffer[drawIndex];
// [Optional] Check if previously visible object
// is frustum culled in the current frame
if (visible)
{
bool frustumCulled = isFrustumCulled(...);
visible &&= !frustumCulled;
}
// Only object that was visible in the
// previous frame should be drawn in the first pass
bool shouldDraw = visible;
if (shouldDraw)
{
// [Optional] Select LOD
...
// Fill indirect draw call arguments
IndirectDrawArgs drawArgs;
...
drawArgs[drawArgsIndex] = drawArgs;
}
在第一次Pass完成后, 可以从生成的深度缓冲区中构建HZB. 与重投影技术生成的近似深度缓冲区相比, 这是一种完全保守的方法.
4.2 第二次Pass
在第二次Pass中, 再次Dispatch一个Compute Shader, 其线程数量与场景中的物体总数相同. 然而, 这一次, 每个线程会对物体执行遮挡剔除, 并可选地进行视锥体剔除和LOD选择, 无论物体在前一次Pass是否可见. 此次Compute Shader的输出结果是一组Indirect Draw Call Arguments, 表示在当前Pass被判定为可见, 但未在第一次Pass渲染的物体. 这些参数会被存储在GPU缓冲区中, 并通过Indirect Draw Call执行, 流程与第一次Pass类似.
$\\$ 为防止重复渲染已在第一次Pass绘制过的物体, 需要跳过前一帧中可见性标记为1的物体. 此外, 无论这些物体是否在第二次Pass被渲染, 均需根据视锥体剔除和遮挡剔除的结果, 动态更新Visibility Buffer, 为下一帧的渲染流程做准备.
..
// [Optional] Check if object is frustum culled in the current frame
bool frustumCulled = isFrustumCulled(...);
bool visible = !frustumCulled;
// Check if object is occlusion culled in the current frame
if (visible)
{
bool occlusionCulled = isOcclusionCulled(...);
visible &&= !occlusionCulled;
}
// Only object that is visible in the current frame
// and was not drawn in the first pass should be drawn in the second pass
bool shouldDraw = visible && !visibilityBuffer[drawIndex];
if (shouldDraw)
{
// [Optional] Select LOD
...
// Fill indirect draw call arguments
IndirectDrawArgs drawArgs;
...
drawArgs[drawArgsIndex] = drawArgs;
}
// Fill visibility buffer for the next frame
visibilityBuffer[drawIndex] = visible;
5. 示例
为了更好地理解该算法, 考虑一个包含5个静态物体与移动摄像机的场景, 其场景设定为:
$\\$ $\cdot$ 静态物体: 5个固定位置的几何体(如立方体, 球体, 建筑模型).
$\\$ $\cdot$ 动态元素: 摄像机沿预设路径移动, 视角随时间变化.
$\\$ $\cdot$ 目标: 通过双Pass遮挡剔除技术, 在单帧渲染中高效剔除不可见物体.
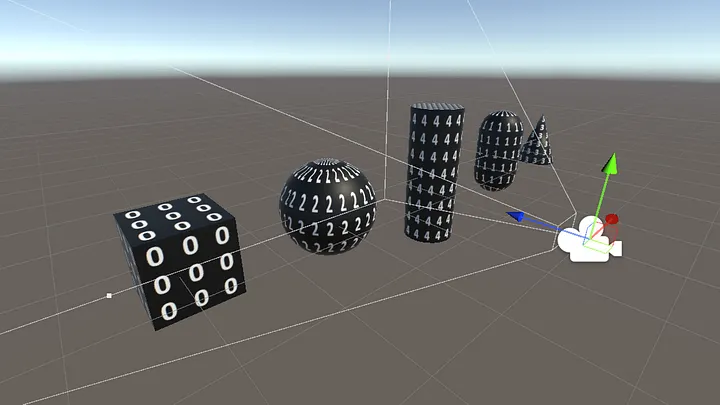
在第一次Pass中, 所有5个物体均会被处理.
$\\$ $\cdot$ 前一帧可见性判断:
$\\$ 1) 若物体在前一帧的Visibility Buffer中标记为0(不可见), 则直接跳过处理.
$\\$ 2) 若标记为1(可见), 则可选执行视锥体剔除和LOD选择.
$\\$ $\cdot$ 示例场景:
$\\$ 1) 假设前一帧中3个物体可见(标记为1), 但因摄像机向左移动, 其中一个物体已移出摄像机视锥体.
$\\$ 2) 若启用了视锥体剔除, 则该物体会被剔除, 最终仅两个物体被渲染, 第三个物体被跳过.


在第二次Pass的处理流程中, 所有物体重新评估可见性. 其中, 第二次Pass的核心逻辑为:
$\\$ $\cdot$ 全量处理: 无论物体在前一帧的可见性状态如何(0 = 不可见, 1 = 可见), 第二次Pass均对场景中的5个物体进行全量处理.
$\\$ $\cdot$ 剔除与优化: 对每个物体执行可选的视锥体剔除, LOD选择和遮挡剔除, 确保仅渲染当前帧真正可见的物体.
$\\$ 对于动态场景变化的处理为:
$\\$ $\cdot$ 新增可见物体: 假设前一帧中有一个物体(如Object3) 因位于摄像机视锥体外(标记为0), 在当前帧中因摄像机移动进入视锥体, 变得可见.
$\\$ $\cdot$ 第二次Pass结果:
$\\$ 1) 第一次Pass已渲染2个物体(如Object1和Object2).
$\\$ 2) 第二次Pass通过剔除测试后, 新增Object3的渲染, 最终总共渲染3个物体.
$\\$ 对于Visibility Buffer的更新处理为:
$\\$ $\cdot$ 动态更新规则:
$\\$ 1) 对通过第二次Pass测试的物体(如Object3), 将其可见性标记更新为1.
$\\$ 2) 对未通过测试的物体(如因遮挡或视锥体剔除的物体), 标记为0.
$\\$ $\cdot$ 目的: 为下一帧的第一次Pass提供最新可见性数据, 确保动态场景的剔除精度.

6. Nanite实际剔除方案(基本上引用自参考材料2)
Nanite最后的双Pass剔除方案其实非常的简单. 之前的想法是上一帧可见的Clusters大概率这帧也可见, 所以拿来当作Occluders. 现在的想法是这一帧可见的Clusters大概率在上一帧也可见, 所以我们把当前帧所有Clusters都转换到上一帧的位置上去, 然后利用上一帧的Hi-$Z$进行遮挡剔除. 最后我们再对被剔除的Clusters进行第二次保守剔除.
$\\$ 乍一看这个方案和大革命有什么不同吗? 难道不都是利用上一帧的$Z$ Buffer吗? 这个方案巧妙的点就在于, 大革命是Reproject上一帧的$Z$ Buffer到当前帧, 而Reprojection会导致漏洞; 而Nanite的方案是利用每个Cluster上一帧的Transform, 把Clusters变换到上一帧的位置下去检测可见信息, $Z$ Buffer本身不需要Reprojection, 这也就不存在漏洞了. PS: 这和笔者若干年做关于RBF逆映射的图形学作业的思路本质上是一样的2333.
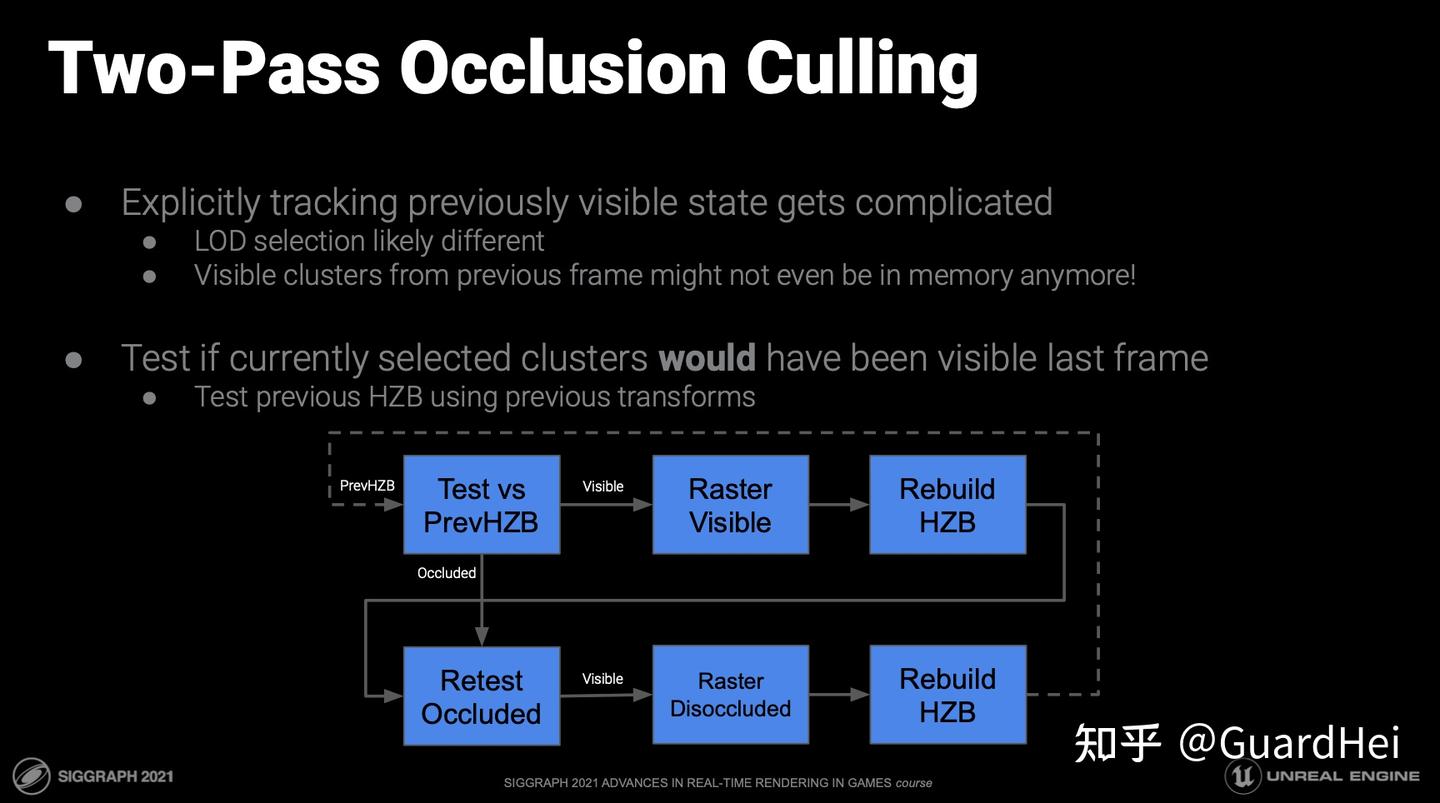
这套操作流程友好: 不需要手动布置Occluders, 也不需要维护复杂的上一帧Clusters队列, 而且由于生成Motion Vectors的需要, 上一帧Clusters的Transforms本来就需要记录, 不需要额外信息; 与此同时性能开销也极大降低: 不用绘制Occluders, 重投影$Z$ Buffer的开销也没了, 转换Clusters到当前帧还是上一帧开销是没有任何区别的, 仅仅是拿的MVP矩阵不同, 而且还不需要对重投影的$Z$ Buffer再生成一次Hi-$Z$ Chain(本来上一帧绘制几何结束就需要再生成一次Hi-$Z$用来加速各种后处理 / Material Binning之类的).
$\\$ 可以说Nanite仅仅在思路上转换了一小步, 就完全把大革命方案的劣势给消除掉了, 这个做法看完了感觉就是”为什么之前没人想到呢?”, 看隔壁COD: Warzone分享还是CPU软渲染Occluders保证Depth准确(当然这可能是项目管理因素了, 反正最后性能也很好).
7. 结论
7.1 双Pass遮挡剔除的核心优势
$\cdot$ 高效剔除不可见物体: 通过第一次Pass继承前一帧可见性数据, 第二次Pass全量处理动态变化, 显著降低GPU渲染负载.
$\\$ $\cdot$ 跨帧一致性: 动态更新Visibility Buffer, 避免画面闪烁(如物体突然出现或消失).
7.2 剧烈运动场景下的性能瓶颈
$\cdot$ 问题描述:
$\\$ 1) 当摄像机与物体发生剧烈相对运动(如过场动画中的镜头快速切换), 可能导致大量物体突然进入视野.
$\\$ 2) 第一次Pass仅处理前一帧可见的物体(如Object1-2), 无法及时处理新增可见物体(如Object0).
$\\$ $\cdot$ 性能影响: 第二次Pass全量处理5个物体时, 新增可见物体(如Object0) 需额外计算HZB遮挡测试和Indirect Draw Call Arguments生成, 导致单帧性能波动.
7.3 双Pass遮挡剔除性能瓶颈解决方案: 引入Depth Prepass
$\cdot$ 实现原理:
$\\$ 1) 在双Pass剔除流程前, 预先渲染所有物体的深度信息(Depth Prepass), 生成保守的HZB.
$\\$ 2) 第一次Pass和第二次Pass直接复用预处理后的HZB, 减少重复计算开销.
$\\$ $\cdot$ 优势:
$\\$ 1) 降低HZB生成频率: 避免每帧因物体剧烈运动重新构建HZB, 提升性能稳定性.
$\\$ 2) 加速遮挡测试: 预处理后的HZB可直接用于双Pass剔除, 减少冗余计算.
7.4 支持不同层级的剔除技术
$\cdot$ Meshlet与三角形剔除:
$\\$ 1) 该技术不仅适用于物体层级剔除, 还可扩展至Meshlet剔除(基于细分网格的可见性测试) 和三角形剔除(逐三角形的遮挡判断).
$\\$ 2) 性能权衡: 三角形剔除因计算开销较大, 通常性价比不高, 但在超精细几何体场景(如Nanite虚拟化几何体) 中可能带来收益.
7.5 跨渲染管线的兼容性
$\cdot$ 支持的渲染架构:
$\\$ 1) 正向渲染: 通过早期剔除减少冗余着色计算.
$\\$ 2) 延迟渲染: 结合G-Buffer优化遮挡剔除效率.
$\\$ 3) 延迟材质: 在材质解析前剔除不可见几何体.
$\\$ 4) Visibility Buffer: 与传统Visibility Buffer区分, 此处指基于Depth Prepass的可见性加速技术.
$\\$ $\cdot$ 高密度几何场景推荐方案: 延迟材质与Visbility Buffer在超大规模几何体(如密度植被, 建筑群) 中表现最佳, 因其能高效处理大量细小遮挡关系.
7.6 现代引擎的GPU驱动趋势
$\cdot$ 行业现状: 大多数现代游戏引擎(如Unreal Engine 5, Unity HDRP) 采用GPU-Driven Rendering架构, 以降低CPU瓶颈.
$\\$ $\cdot$ 双Pass剔除的优势:
$\\$ 1) 轻量级实现: 仅需两次Pass中使用Compute Shader与更新Visibility Buffer, 适配GPU并行计算特性.
$\\$ 2) 性能增益: 在复杂场景中可减少Draw Calls与Pixel Shader负载.
$\\$ $\cdot$ 行业采纳预测: 鉴于其实现简单与性能收益显著, 预计将成为主流引擎的标准剔除方案.